XLDB 2013 Examines 'Big Data' Projects
If Benjamin Franklin were alive today, he would likely extend his often-quoted list of life's certainties – death and taxes – to include more and more data. SLAC computer scientist Jacek Becla couldn't agree more. As founder of the Extremely Large Databases (XLDB) conference, which serves people who work with datasets too large or complex for conventional solutions, Becla is intimately aware of the information explosion.
By Mike Ross
If Benjamin Franklin were alive today, he would likely extend his often-quoted list of life's certainties – death and taxes – to include more and more data.
SLAC computer scientist Jacek Becla couldn't agree more. As founder of the Extremely Large Databases (XLDB) conference, which serves people who work with datasets too large or complex for conventional solutions, Becla is intimately aware of the information explosion.
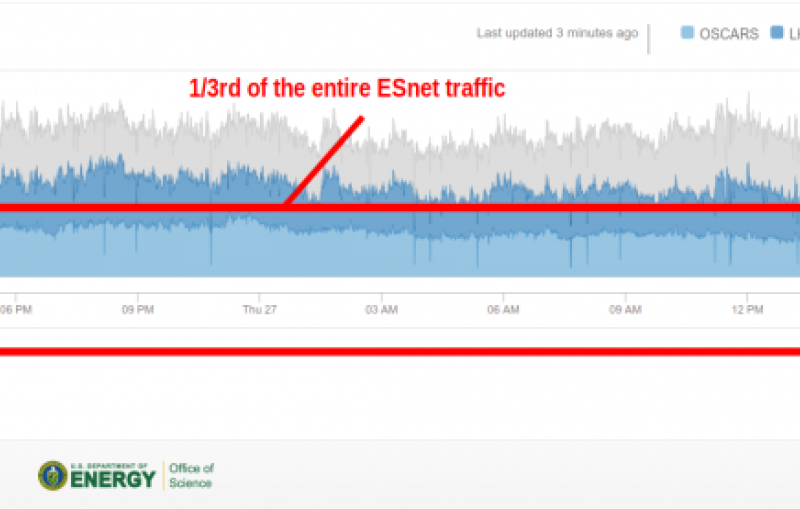
Just 10 years ago, all the world's data sources produced an estimated 5 exabytes, or billion billion bytes, of information in a year. In the past year alone, by comparison, a single detector at the Large Hadron Collider produced more than a thousand exabytes of data, said SLAC's Richard Mount at the seventh annual XLDB conference, held earlier this month on the Stanford campus.
As the databases that hold all this information become extremely large, some key features – such as indexes – drag rather than improve performance. The community comes to XLDB to learn new ideas for overcoming the challenges that come with such huge data stores.
The theme of this year's conference was how "big data" projects are created. Speakers gave perspectives from industry and science as well as from funding sources, such as the National Science Foundation and venture capitalists.
"There is still a gulf between scientific and industrial projects," Becla said. "Government funding agencies are understandably conservative when funding huge science projects, such as accelerators or telescopes." They often lock in technology early in a project's development.
Commercial data projects, on the other hand, have much shorter development time scales and often must be able to change to accommodate rapidly changing needs. Google and Facebook, for example, use open source databases so they can take advantage of enhancements created by their wide-ranging user communities. It can be a headache to keep up. "Every year we see last year's best solutions fading away, superseded by newer ones," Becla said.
In both cases, the motivation is the same: avoiding failure.
"When governments are spending so much money – perhaps billions of dollars – on a huge hardware project, you absolutely can't drop the data," Becla said. "Likewise, commercial projects have to continue to improve performance without any outages. They build flexible, redundant systems and must include complicated schemes for seamless migrations and upgrades across their huge networks.”
As Google's Jeremy Cole said in his talk: "Databases are fun … until you use them."
Begun in 2007 as a small, invitation-only workshop, XLDB has grown into a large, internationally recognized annual conference and a community of more than 1,000 computer scientists, researchers and industry experts who work with extremely large databases. All but one of the conferences have been held at SLAC or Stanford. In recent years, satellite workshops have also been held in Scotland, Switzerland and China.
Last year's talks had more than 10,000 YouTube views. The talks for the 2013 conference have recently become available on YouTube as well.
Becla said future XLDB conferences will probably be held in the spring, which is more convenient for both academic and European researchers. If so, the next full conference would be held in 2015, he said, and two satellite workshops would be set for next year, probably in Brazil and Asia.
SLAC recently received a $100,000 grant from the Gordon and Betty Moore Foundation to create and bootstrap a system for publishing XLDB "use case" information on how a variety of organizations manage their huge databases.
Contact
For questions or comments, contact the SLAC Office of Communications at communications@slac.stanford.edu.